Una vez solucionado el error mostrado en el post anterior, recibí el siguiente mensaje cuando intentaba ejecutar la aplicación generada:
“Bad CPU type in executable”
Para solucionar este problema busque cómo ejecutar una aplicación MAUI en una Mac que utiliza un procesador M2.
Lo primero que busqué es que puede estar causando este error y me encontré que hay dos posibles causas:
Mac M2 no soporta los programas de 32 bits a partir de Catalina OS, por lo tanto, tratar de instalar un programa que no es de 64 bits o que tiene algunas librerías de 32 bits va a provocar este error.
Migración de procesador de Intel a procesadores Apple Silicon. Cuando se dio el reemplazo de los procesadores de Intel a los procesadores M1 provocó que las aplicaciones diseñadas para los procesadores Intel no funcionaran en las Macs basadas en ARM64 - esta es la causa más común.
Para solucionar este problema cuando es causado por la razón 2 antes expuesta - mi caso - se debe instalar un traductor binario dinámico que se agregó por primera vez en el sistema operativo MacOS Big Sur. Este traductor lo que hace es traducir las aplicaciones basadas en los procesadores Intel para que puedan correr en los procesadores de Apple sin modificar el código, específicamente traduce instrucciones x86_64 por instrucciones ARM.
Este traductor se llama Rosetta 2 y en mi caso lo instalé desde el terminal del sistema operativo. La instrucción a ejecutar es la siguiente:
/usr/sbin/softwareupdate -install-rosetta -agree-to-license
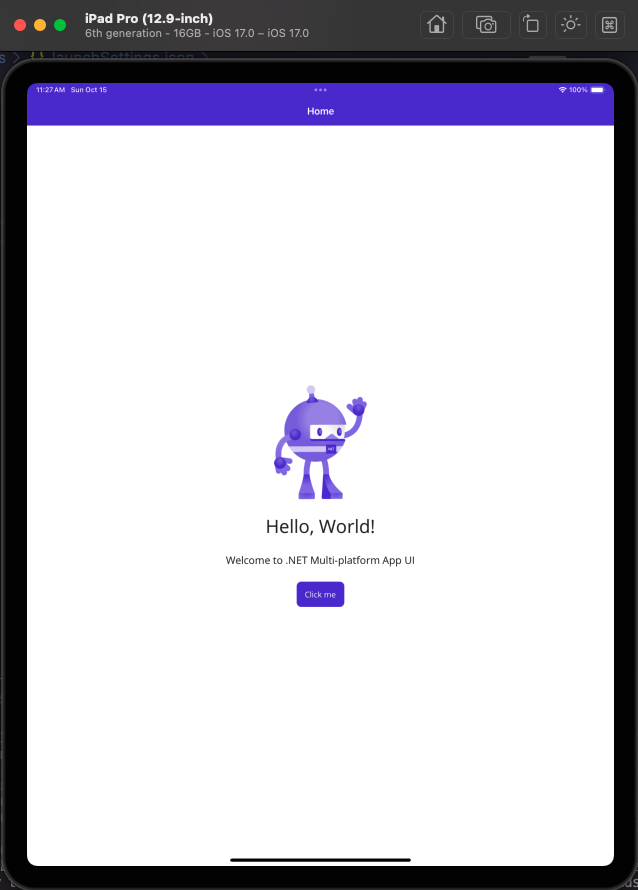
Una vez ejecutada la instrucción procedemos a ejecutar el programa que ha generado la instrucción dotnet new. Para llevar a cabo esta ejecución procedemos con el siguiente comando:
dotnet build -t:Run -f net8.0-ios
El resultado de la ejecución de dicho comando se puede ver en la siguiente figura.